If you need to migrate your SQL database from say, MySQL to MSSQL, you should know that most SQL implementation differ in some trivial and some core ways that may make the migration very difficult and anoying.
Before you choose to migrate SQL implementations I recomend you to check this link with information about the differences in the most popular SQL implementations (MySQL, Postgres, MMSQL, Oracle and DB2).
Monday, November 13, 2006
Saturday, November 11, 2006
Web 2.0 Network Management
Before working as a programmer I was a network administrator for a metropolitan ATM network. I had to deal with more than 500 network devices all over the city including servers, routers, ATM switches and cable modem CPE's.
To handle the daunting task of monitoring all the interfaces and services of all these equipments I tried a lot of tools from commercial solutions like IBM Tivoli, open source solutions like NetSaint, BigBrother and my own custom solutions with perl, mrtg and net snmp. In this blog I will tell you about my experiences in the field of network management.
The company I worked bought the IBM Tivoli Framework for the network management task. After months in trainings, setup, IBM consultants and technical staff coming and going and expending thousands of dollars in equipment,training and support we ended with a complete, ultra powerful and insanely complex system for network management. Too bad no one ever used it fully, not because we did not know how to use it but because we had no actual use for it.
All we wanted was to monitor a set of network devices via SNMP. The network monitor had to be configured with IP address and auto detect via snmp the interfaces, add them to the system, monitor them (traffic, errors, etc). The Tivoli Netview was more than sufficient for this but the sales guys at IBM would insist that we would also need the Tivoli Access Manager, Tivoli Identity Manager, Tivoli Directory Integrator, Tivoli Directory Server, Tivoli Storage Manager and lot more stuff. Each of these products came with a server, lost's of manuals, training, etc.
We tried to use these Tivoli things, since our company payed huge amounts of money for it, but no matter how hard we tried these systems had no use for us. Even the Tivoli NetView was not that useful. It was unable to autodetect correctly the interfaces of our CISCO routers and gave us ambiguous names and descriptions for out ATM Switches interfaces.
This really was not a NetView problem, the fault was on the ATM Switches manufacturer that put the wrong descriptions in their SNMP MIB. We had to manually edit the descriptions of each device interface and there were a LOT. The NetView GUI was far from fluid and each interface had to be edited one by one using like 5 different dialog boxes for each one.
The more we used Tivoli's NetView (the other Tivoli servers were accumulating dust and consuming power only) we were more convinced we needed to throw it away and so we did. As linux enthusiasts we started looking in the open source camp.
We played with open source monitoring solutions like NetSaint (now Nagios) and BigBrother and they are good but we must face it, web interfaces (at that time) were not the best in terms of usability and speed.
In the end we simply developed our own perl scripts with snmp and MRTG in linux. The linux console interface (with the GNU tools) is very powerful if you know how to use it, perl was perfect to handle large amounts of text data (mrtg cfg files) and mrtg combined with snmp command tools was simple and more that enough to our needs.
With our scripts we got a complete solution and we were happy but as time passed and people started finishing graduate school and moving to other companies (including me) the inners of out custom solution became taboo and black magic for those that came after us. Also there are now better tools like RRD Tool and Ruby that could be used to improve or replace the system.
A few days ago I read an article about Nagios and started thinking that these web based monitoring applications in the back end are really using the same tools I used like perl, mrtg, snmp. If only the interface was more fluid/flexible as to give the impression of a desktop application and real time monitoring it could become the next big application. Suddenly it hit my head: Wait! Web 2.0 is about exactly that!! make web interfaces more fluid and flexible as desktop applications!! I felt as if it was the discovery of the century and started to get ideas on how to develop such applications using Ruby/Rails/GoogleMaps/RRDTool.
Well my excitement only lasted a few minutes. After some thinking I realized that first: I have no time to do such thing, and second: Google showed me that this is not a discovery and that there are already implmentations of Web2.0 monitoring systems. See here, here, here and here for some examples.
Well these applications are still in diapers and there is a lot of space for improvement. Maybe when I finish school I will do something like this. With my experience as network administrator and now as professional programmer I may get something good...
To handle the daunting task of monitoring all the interfaces and services of all these equipments I tried a lot of tools from commercial solutions like IBM Tivoli, open source solutions like NetSaint, BigBrother and my own custom solutions with perl, mrtg and net snmp. In this blog I will tell you about my experiences in the field of network management.
The company I worked bought the IBM Tivoli Framework for the network management task. After months in trainings, setup, IBM consultants and technical staff coming and going and expending thousands of dollars in equipment,training and support we ended with a complete, ultra powerful and insanely complex system for network management. Too bad no one ever used it fully, not because we did not know how to use it but because we had no actual use for it.
All we wanted was to monitor a set of network devices via SNMP. The network monitor had to be configured with IP address and auto detect via snmp the interfaces, add them to the system, monitor them (traffic, errors, etc). The Tivoli Netview was more than sufficient for this but the sales guys at IBM would insist that we would also need the Tivoli Access Manager, Tivoli Identity Manager, Tivoli Directory Integrator, Tivoli Directory Server, Tivoli Storage Manager and lot more stuff. Each of these products came with a server, lost's of manuals, training, etc.
We tried to use these Tivoli things, since our company payed huge amounts of money for it, but no matter how hard we tried these systems had no use for us. Even the Tivoli NetView was not that useful. It was unable to autodetect correctly the interfaces of our CISCO routers and gave us ambiguous names and descriptions for out ATM Switches interfaces.
This really was not a NetView problem, the fault was on the ATM Switches manufacturer that put the wrong descriptions in their SNMP MIB. We had to manually edit the descriptions of each device interface and there were a LOT. The NetView GUI was far from fluid and each interface had to be edited one by one using like 5 different dialog boxes for each one.
The more we used Tivoli's NetView (the other Tivoli servers were accumulating dust and consuming power only) we were more convinced we needed to throw it away and so we did. As linux enthusiasts we started looking in the open source camp.
We played with open source monitoring solutions like NetSaint (now Nagios) and BigBrother and they are good but we must face it, web interfaces (at that time) were not the best in terms of usability and speed.
In the end we simply developed our own perl scripts with snmp and MRTG in linux. The linux console interface (with the GNU tools) is very powerful if you know how to use it, perl was perfect to handle large amounts of text data (mrtg cfg files) and mrtg combined with snmp command tools was simple and more that enough to our needs.
With our scripts we got a complete solution and we were happy but as time passed and people started finishing graduate school and moving to other companies (including me) the inners of out custom solution became taboo and black magic for those that came after us. Also there are now better tools like RRD Tool and Ruby that could be used to improve or replace the system.
A few days ago I read an article about Nagios and started thinking that these web based monitoring applications in the back end are really using the same tools I used like perl, mrtg, snmp. If only the interface was more fluid/flexible as to give the impression of a desktop application and real time monitoring it could become the next big application. Suddenly it hit my head: Wait! Web 2.0 is about exactly that!! make web interfaces more fluid and flexible as desktop applications!! I felt as if it was the discovery of the century and started to get ideas on how to develop such applications using Ruby/Rails/GoogleMaps/RRDTool.
Well my excitement only lasted a few minutes. After some thinking I realized that first: I have no time to do such thing, and second: Google showed me that this is not a discovery and that there are already implmentations of Web2.0 monitoring systems. See here, here, here and here for some examples.
Well these applications are still in diapers and there is a lot of space for improvement. Maybe when I finish school I will do something like this. With my experience as network administrator and now as professional programmer I may get something good...
Friday, November 10, 2006
Scrapping japanese web pages with Ruby and Mechanize
With WWW::Mechanize it is possible to scrap all kinds of web pages no matter if they require sessions, complicated forms, or have difficult/bad html syntax. So why the emphasis of "japanese" in the title you ask??. Do we need a Japanese version of Mechanize to scrap Japanese characters??. Well the answer to the second question is NO, but we still need to be carefull when scrapping Japanese html pages.
If you have to scrap several Japanese html pages from different places you will find that in Japan there are three standard encodings used for the text in html pages, namely EUC-JP, Shift-JIS and UTF-8. At first I was using the content-type of the html header to determine the page encoding and then convert the page to Shift-JIS encoding that is the encoding used by the MSSQL database where I store the scrapped data.
Unfortunately as more pages I scrapped it was clear that the validity of the content-type field depends on how serious is the html page developer. Some pages were missing the charset parameter in the content-type and others even had it wrong (charset=sjis in a UTF encoded page). Suddenly I was testing every page to find out the encoding before scrapping it and had three ruby scripts, one for each type of encoding.
Later I learned that ruby actually has ways to find out automatically between the three encodings by checking the text itself (no wonder since Ruby was developed in Japan). This capability combined with the flexibility of Mechanize allowed me to write a single script to extract any japanese page without concerns in encodings : ).
The magic is done by Kconv (Ruby Kanji Converter) that has methods to convert any string to an specific encoding. Kconv makes some guesses on the current encoding of the string and then makes the necessary steps to convert it to the desired one.
To integrate Kconv with Mechanize we take advantage of the pluggable parsers:
There is nothing new in this code with respect to Mechanize but if you do not understand what this code does the you should read the GUIDE file that comes with Mechanize. The important line here is the one marked Magic Line. This simple line of code uses Kconv to convert whatever it receives (the html page) to Shift-Jis encoding. The encoded html page is then used to create a Page object as Mechanize would normaly do. No matter if the page is in UTF, EUC or SJIS encoding the result will be a Page object with the body in Shift-JIS encoding. Pretty cool isn't it?
The code above works well for Mechanize 0.5.1 and 0.6.0 that support pluggable parsers but in Mechanize 0.4.7 there are no pluggable parsers.In Mechanize 0.4.7 we have a less flexible "body_filter" that can be used to encode the html pages before they are parsed by Mechanize.
Again the magic is marked by the Magic Line line. From the Mechanize documentation:
The body filter sends the page body to the code block, and parses what the code block returns. The filter on WWW::Page#body_filter is a "per-page" filter, meaning that it is only applied to one page object.
In short we convert the html to Shift-Jis before it is parsed by Mechanize.
Warning!!: There is a small difference on how body_filter works in comparison to the pluggable parser presented above. The body_filter will encode the html text to sjis and the result will be passed to the parser for further processing. The body_filter WILL NOT modify the html text itself!!. If you print out the html text using "puts page.body" you will get the html text in the original encoding. Only the parsed html will be in Shift-JIS and that is why I only print the links text the example above.
In the case of the pluggable parser we convert the html text and pass the encoded version to the Page class initialize method. This way the Page object is created with the Shift-JIS encoded version from the start.
If you need to access the encoded html text it is possible to exploit the openness of Ruby classes and modify the Page class to do it. For this we simply redefine the "body" method from the Page class as follows:
There is no limit to the flexibility that Ruby offers us. With the definition of the Page class in the above code we are modifiying the way Mechanize works without need to change anything in the original Mechanize source. Now we can use the "body" method to obtaing the Shift-JIS encoded version of the html text. Moreover we could go rampant and add methods to get the body in different encodings like:
We see here that Ruby and everything Ruby related is powerfull and flexible without being too complicated. I am still learning and the more I learn the more I am stick with it. If only there were MIDP/CLDC implementations in Ruby... Have fun scrapping japanese pages!
If you have to scrap several Japanese html pages from different places you will find that in Japan there are three standard encodings used for the text in html pages, namely EUC-JP, Shift-JIS and UTF-8. At first I was using the content-type of the html header to determine the page encoding and then convert the page to Shift-JIS encoding that is the encoding used by the MSSQL database where I store the scrapped data.
Unfortunately as more pages I scrapped it was clear that the validity of the content-type field depends on how serious is the html page developer. Some pages were missing the charset parameter in the content-type and others even had it wrong (charset=sjis in a UTF encoded page). Suddenly I was testing every page to find out the encoding before scrapping it and had three ruby scripts, one for each type of encoding.
Later I learned that ruby actually has ways to find out automatically between the three encodings by checking the text itself (no wonder since Ruby was developed in Japan). This capability combined with the flexibility of Mechanize allowed me to write a single script to extract any japanese page without concerns in encodings : ).
The magic is done by Kconv (Ruby Kanji Converter) that has methods to convert any string to an specific encoding. Kconv makes some guesses on the current encoding of the string and then makes the necessary steps to convert it to the desired one.
To integrate Kconv with Mechanize we take advantage of the pluggable parsers:
require 'rubygems'
require 'mechanize'
require 'kconv'
# Create a pluggable parser
class SjisParser < WWW::Mechanize::Page
def initialize(uri = nil, response = nil, body = nil, code = nil)
body = Kconv.tosjis(body) # Magic Line
super(uri, response, body, code)
end
end
# Create the WWW::Mechanize object
agent = WWW::Mechanize.new
# Register our parser
agent.pluggable_parser.html = SjisParser
# Load the UTF or EUCJP encoded page
page = agent.get("http://utf-or-eucjp/encoded/page.html")
# Print the result
puts page.body
There is nothing new in this code with respect to Mechanize but if you do not understand what this code does the you should read the GUIDE file that comes with Mechanize. The important line here is the one marked Magic Line. This simple line of code uses Kconv to convert whatever it receives (the html page) to Shift-Jis encoding. The encoded html page is then used to create a Page object as Mechanize would normaly do. No matter if the page is in UTF, EUC or SJIS encoding the result will be a Page object with the body in Shift-JIS encoding. Pretty cool isn't it?
The code above works well for Mechanize 0.5.1 and 0.6.0 that support pluggable parsers but in Mechanize 0.4.7 there are no pluggable parsers.In Mechanize 0.4.7 we have a less flexible "body_filter" that can be used to encode the html pages before they are parsed by Mechanize.
require 'rubygems'
require_gem 'mechanize', '=0.4.7' # Make sure we are using version 0.4.7
require 'mechanize'
require 'kconv'
# Create the WWW::Mechanize object
agent = WWW::Mechanize.new
page = agent.get("http://utf-or-eucjp/encoded/page.html")
page.body_filter = lambda { |body| Kconv.tosjis(body) } # Magic Line
# Print the links text
puts page.links.each { |link| puts link.text }
Again the magic is marked by the Magic Line line. From the Mechanize documentation:
The body filter sends the page body to the code block, and parses what the code block returns. The filter on WWW::Page#body_filter is a "per-page" filter, meaning that it is only applied to one page object.
In short we convert the html to Shift-Jis before it is parsed by Mechanize.
Warning!!: There is a small difference on how body_filter works in comparison to the pluggable parser presented above. The body_filter will encode the html text to sjis and the result will be passed to the parser for further processing. The body_filter WILL NOT modify the html text itself!!. If you print out the html text using "puts page.body" you will get the html text in the original encoding. Only the parsed html will be in Shift-JIS and that is why I only print the links text the example above.
In the case of the pluggable parser we convert the html text and pass the encoded version to the Page class initialize method. This way the Page object is created with the Shift-JIS encoded version from the start.
If you need to access the encoded html text it is possible to exploit the openness of Ruby classes and modify the Page class to do it. For this we simply redefine the "body" method from the Page class as follows:
require 'rubygems'
require_gem 'mechanize', '=0.4.7' # Make sure we are using version 0.4.7
require 'mechanize'
require 'kconv'
# Redefine the body method of the Page class
module WWW
class Page
def body
Kconv.tosjis(@body)
end
end
end
# Create the WWW::Mechanize object
agent = WWW::Mechanize.new
page = agent.get("http://utf-or-eucjp/encoded/page.html")
page.body_filter = lambda { |body| Kconv.tosjis(body) } # Magic Line
# Print the Shift-JIS encoded body
puts page.body
There is no limit to the flexibility that Ruby offers us. With the definition of the Page class in the above code we are modifiying the way Mechanize works without need to change anything in the original Mechanize source. Now we can use the "body" method to obtaing the Shift-JIS encoded version of the html text. Moreover we could go rampant and add methods to get the body in different encodings like:
require 'rubygems'
require_gem 'mechanize', '=0.4.7' # Make sure we are using version 0.4.7
require 'mechanize'
require 'kconv'
# Redefine the Page class
module WWW
class Page
# Return the body Shift-JIS encoded
def sjis_body
Kconv.tosjis(@body)
end
# Return the body EUC-JP encoded
def euc_body
Kconv.toeuc(@body)
end
# Return the body UTF-8 encoded
def utf8_body
Kconv.toutf8(@body)
end
end
end
We see here that Ruby and everything Ruby related is powerfull and flexible without being too complicated. I am still learning and the more I learn the more I am stick with it. If only there were MIDP/CLDC implementations in Ruby... Have fun scrapping japanese pages!
Linux can do almost anything!
I like to browse linux application pages like sourceforge, kde-apps and freshmeat just to see what cool applications are there to play with. There are always little gems not known to the general public and who knows? there may be the next killer application waiting to be discovered.
After years of browsing these pages you will see that you can do almost anything with linux and on more than one way. Granted that most of the applications you see are not active, are pet projects of someone or were student projects that are no longer being developed. But this does not mean that all of the projects are of no use, lots of good projects are there to be discovered that can be usefull and maybe become the next big thing. Did you know that most popular applications today started as small pet projects or student projects of someone?.
Some of the little known applications I use are the Japanese dictionary software for kde, Kiten, the bible study software, Sword, the cool quake like console Yakuake and little eye candy apps like xsnow, xpenguins and amor.
One of my all favorite tools is x2vnc/win2vnc to share a single mouse/keyboard between different computers running different OS.
Another way to find applications is to browse your distro software repository. This way you can also install/unintall the software using your distro management tools with a few clicks/commands. For example in gentoo simply browse the /usr/portage directory to find out what softwares are avaliable and in kubuntu you can browse the list of available apps using adept.
With time browsing applications you will agree with me that almost anything can be done using linux. I mean you can even make coffee and brew beer with linux!
After years of browsing these pages you will see that you can do almost anything with linux and on more than one way. Granted that most of the applications you see are not active, are pet projects of someone or were student projects that are no longer being developed. But this does not mean that all of the projects are of no use, lots of good projects are there to be discovered that can be usefull and maybe become the next big thing. Did you know that most popular applications today started as small pet projects or student projects of someone?.
Some of the little known applications I use are the Japanese dictionary software for kde, Kiten, the bible study software, Sword, the cool quake like console Yakuake and little eye candy apps like xsnow, xpenguins and amor.
One of my all favorite tools is x2vnc/win2vnc to share a single mouse/keyboard between different computers running different OS.
Another way to find applications is to browse your distro software repository. This way you can also install/unintall the software using your distro management tools with a few clicks/commands. For example in gentoo simply browse the /usr/portage directory to find out what softwares are avaliable and in kubuntu you can browse the list of available apps using adept.
With time browsing applications you will agree with me that almost anything can be done using linux. I mean you can even make coffee and brew beer with linux!
Wednesday, November 08, 2006
Better Bash prompt
More colorfull and useful bash prompt
Here is what I did to give a little more color and style to my bash prompt following this blog post:
Edit the .bashrc file in your home directory and define your PS1 env variable in the section that looks like this:
# Comment in the above and uncomment this below for a color prompt
PS1='\[\e[32m\][\u@\h]\[\e[0m\]\[\e[37m\][\t]\[\e[0m\]\n\[\e[34m\][\w]\[\e[0m\]> '
Make sure to replace the PS1 value to anything you prefer. For more information on the meaning of the PS1 values check the Bash-Prompt How-To.
To make the change take effect in the current bash session simply source the .bashrc file like:
[~]> source ~/.bashrc
Here is what I did to give a little more color and style to my bash prompt following this blog post:
Edit the .bashrc file in your home directory and define your PS1 env variable in the section that looks like this:
# Comment in the above and uncomment this below for a color prompt
PS1='\[\e[32m\][\u@\h]\[\e[0m\]\[\e[37m\][\t]\[\e[0m\]\n\[\e[34m\][\w]\[\e[0m\]> '
Make sure to replace the PS1 value to anything you prefer. For more information on the meaning of the PS1 values check the Bash-Prompt How-To.
To make the change take effect in the current bash session simply source the .bashrc file like:
[~]> source ~/.bashrc
X11 for Windows
As a normal geek I have access to a large number of computers at work, school and home. To avoid duplication of information (i.e. emails, bookmarks and files spread among several computers) I usually have all my data and applications on my computer at home and use X-Forwarding to access it remotely from work and school.
This works great when I have access to Linux computers at work and school (I usually do) but in some rare situations I end surrounded by Windows only computers. Fortunately there are ways to get X-Forwarding to work in a Windows environment and here I explain the method I use.
X11 server for Windows
For X11 based applications (i.e. all Linux applications with GUI) to be displayed on Windows we need an implementation of X11 for Windows. I chose to use XMing that is small, easy to install and just works out of the box.
For installation simply follow these instruction and you are good to go.
SSH Client for Windows
To connect to the remote machine (i.e. home machine) with X-Forwarding support we need a good ssh client for Windows. I have used PuTTY and OpenSSH with success. If you prefer command line use OpenSSH or if you like a GUI ssh client then use PuTTY as both are equally functional and feature rich.
For instruction on how to get and install PuTTY look at this link.
X-Forwarding with OpenSSH on Windows
If you prefer to use OpenSSH command line instead of PuTTY GUI you need to install the package from http://sshwindows.sourceforge.net/.
Simply download and install the most recent self installation package and from the command prompt you will be able to run ssh with all it's command line options and features. For X-Forwarding make sure that XMing is running and then run the ssh command with the -C and -X command switches to connect to the remote machine.
As you see it is important to set the DISPLAY environment variable before running the ssh command. Without this environment variable all X11 applications will be unable to find the XMing display and fail to start. Normally the DISPLAY used by XMing is 127.0.0.1:0.0 but in case it is not you can find the value looking at the XMing log files.
The -CX switch simply means to enable compression (-C) and X-Forwarding (-X). Read the ssh documentation for more command switches and options.
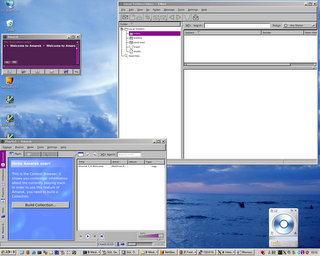
Mandatory Screenshots
First we see my favorite mail client (Kmail) in conjunction with my favorite music jukebox (Amarok).
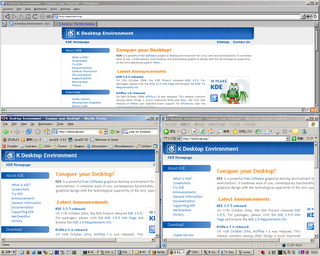
This second screenshot you can see Konqueror, Firefox and IE in the same machine with the KDE page loaded.
Final Remarks
Remember that this is NOT running Linux applications on a Windows PC. The KDE applications you see in the screenshots are running at a remote computer (my home computer) that has Linux (Kubuntu) installed. The X11 client (XMing) only displays the applications on the Windows PC and allows you to interact with them via mouse and keyboard.
Also note that you need to enable X11 forwarding at the server side and have Xorg or Xfree server installed. In Kubuntu these are the default settings so no change is needed at the server side except for installing the openssh-server.
Little Drawback
Using XMing to run remote X11 applications in a Windows PC is very useful and it works perfectly except for one little drawback: the system tray . Applications like Amarok, KMail, Akregator, Kopete when configured to use the system tray will try to dock on the system tray when minimized but on XMing they will simply disappear with no way (that I can find) to get them back. So if you use XMing try to avoid using the system tray.
This works great when I have access to Linux computers at work and school (I usually do) but in some rare situations I end surrounded by Windows only computers. Fortunately there are ways to get X-Forwarding to work in a Windows environment and here I explain the method I use.
X11 server for Windows
For X11 based applications (i.e. all Linux applications with GUI) to be displayed on Windows we need an implementation of X11 for Windows. I chose to use XMing that is small, easy to install and just works out of the box.
For installation simply follow these instruction and you are good to go.
SSH Client for Windows
To connect to the remote machine (i.e. home machine) with X-Forwarding support we need a good ssh client for Windows. I have used PuTTY and OpenSSH with success. If you prefer command line use OpenSSH or if you like a GUI ssh client then use PuTTY as both are equally functional and feature rich.
For instruction on how to get and install PuTTY look at this link.
X-Forwarding with OpenSSH on Windows
If you prefer to use OpenSSH command line instead of PuTTY GUI you need to install the package from http://sshwindows.sourceforge.net/.
Simply download and install the most recent self installation package and from the command prompt you will be able to run ssh with all it's command line options and features. For X-Forwarding make sure that XMing is running and then run the ssh command with the -C and -X command switches to connect to the remote machine.
SET DISPLAY=127.0.0.1:0.0
ssh -CX -l username remote_ip_address
As you see it is important to set the DISPLAY environment variable before running the ssh command. Without this environment variable all X11 applications will be unable to find the XMing display and fail to start. Normally the DISPLAY used by XMing is 127.0.0.1:0.0 but in case it is not you can find the value looking at the XMing log files.
The -CX switch simply means to enable compression (-C) and X-Forwarding (-X). Read the ssh documentation for more command switches and options.
Mandatory Screenshots
First we see my favorite mail client (Kmail) in conjunction with my favorite music jukebox (Amarok).

This second screenshot you can see Konqueror, Firefox and IE in the same machine with the KDE page loaded.

Final Remarks
Remember that this is NOT running Linux applications on a Windows PC. The KDE applications you see in the screenshots are running at a remote computer (my home computer) that has Linux (Kubuntu) installed. The X11 client (XMing) only displays the applications on the Windows PC and allows you to interact with them via mouse and keyboard.
Also note that you need to enable X11 forwarding at the server side and have Xorg or Xfree server installed. In Kubuntu these are the default settings so no change is needed at the server side except for installing the openssh-server.
sudo aptitude install openssh-server
Little Drawback
Using XMing to run remote X11 applications in a Windows PC is very useful and it works perfectly except for one little drawback: the system tray . Applications like Amarok, KMail, Akregator, Kopete when configured to use the system tray will try to dock on the system tray when minimized but on XMing they will simply disappear with no way (that I can find) to get them back. So if you use XMing try to avoid using the system tray.
Monday, November 06, 2006
Tips on RubyGems: Installation and Versioning
Installing RubyGems in Kubuntu
Kubuntu has it's own packaging system for software (deb files) that can be conveniently installed/uninstalled from your installation with a few clicks using adept or a few commands using apt-get/aptitude.
Unfortunately most of the ruby libraries I use at work are not yet in the Kubuntu repositories so I usually resort to the RubyGems packaging system to manage those libraries (gems). It seems there are conflicts in the way these two packaging systems manage the ruby libraries so RubyGems seems to be banned from he Kubuntu repositories requiring us to install it manually. Fortunately it is very easy to do and here is how I do it:
Now you can use the gems command to search, install and uninstall your favorite Ruby libraries like Mechanize and rMagick.
Specifying Gem Versions in Ruby scripts
There seems to be some misleading (or erroneous?) documentation on the RubyGems User Guide about using specific versions of a particular gem in a ruby script. In the section "Using Explicit Versions" the example indicates that a single call to require_gem with the version as second argument is enough to load that particular version of the gem in our script. For example to use Mechanize version 0.4.7 that is incompatible with 0.6.0 the user guide indicates the following steps:
If you try this and create a WWW::Mechanize object ruby will complain with a NameError like this one:
The problem seems to be that the require_gem does sets the gem version you want but it does not load the gem. So after the require_gem directive you need to explicitly load the mechanize gem as follows:
As you see I explicitly load the mechanize library after specifying the version with require_gem. After this you can now easily use Mechanize version 0.4.7 in your script.
In windows installations using the One-Click Ruby Installer it is also necessary to load the gem after specifying the version with require_gem.
Install the Mechanize Gem in Kubuntu
Note that to use Mechanize with ruby in Kubuntu you need the libopenssl-ruby deb installed or you will get errors like "LoadError: no such file to load -- net/https" when loading mechanize. To install the libopenssl-ruby deb simply run:
Kubuntu has it's own packaging system for software (deb files) that can be conveniently installed/uninstalled from your installation with a few clicks using adept or a few commands using apt-get/aptitude.
Unfortunately most of the ruby libraries I use at work are not yet in the Kubuntu repositories so I usually resort to the RubyGems packaging system to manage those libraries (gems). It seems there are conflicts in the way these two packaging systems manage the ruby libraries so RubyGems seems to be banned from he Kubuntu repositories requiring us to install it manually. Fortunately it is very easy to do and here is how I do it:
# Make sure everything is up to date
sudo aptitude update
sudo aptitude dist-upgrade
# Install ri and rdoc needed for RubyGems to work
sudo aptitude install ri rdoc
# Install RubyGems
wget http://rubyforge.org/frs/download.php/11289/rubygems-0.9.0.tgz
tar zxvf rubygems-0.9.0.tgz
cd rubygems-0.9.0
sudo ruby setup.rb
Now you can use the gems command to search, install and uninstall your favorite Ruby libraries like Mechanize and rMagick.
Specifying Gem Versions in Ruby scripts
There seems to be some misleading (or erroneous?) documentation on the RubyGems User Guide about using specific versions of a particular gem in a ruby script. In the section "Using Explicit Versions" the example indicates that a single call to require_gem with the version as second argument is enough to load that particular version of the gem in our script. For example to use Mechanize version 0.4.7 that is incompatible with 0.6.0 the user guide indicates the following steps:
require 'rubygems'
require_gem 'mechanize', '= 0.4.7'
If you try this and create a WWW::Mechanize object ruby will complain with a NameError like this one:
NameError: unitialized constant WWW
The problem seems to be that the require_gem does sets the gem version you want but it does not load the gem. So after the require_gem directive you need to explicitly load the mechanize gem as follows:
require 'rubygems'
require_gem 'mechanize', '= 0.4.7'
require 'mechanize'
As you see I explicitly load the mechanize library after specifying the version with require_gem. After this you can now easily use Mechanize version 0.4.7 in your script.
In windows installations using the One-Click Ruby Installer it is also necessary to load the gem after specifying the version with require_gem.
Install the Mechanize Gem in Kubuntu
Note that to use Mechanize with ruby in Kubuntu you need the libopenssl-ruby deb installed or you will get errors like "LoadError: no such file to load -- net/https" when loading mechanize. To install the libopenssl-ruby deb simply run:
sudo aptitude install libopenssl-ruby
Subscribe to:
Posts (Atom)